Recommender Systems: The Most Valuable Application of Machine Learning (Part 2)
Why Recommender Systems are the most valuable application of Machine Learning and how Machine Learning-driven Recommenders already drive almost every aspect of our lives.
Why Recommender Systems are the most valuable application of Machine Learning and how Machine Learning-driven Recommenders already drive almost every aspect of our lives.
This is the second part of the article published on 11 May. In the first part I covered:
- Business Value
- Problem Formulation
- Data
- Algorithms
In this second part I will cover the following topics:
- Evaluation Metrics
- User Interface
- Cold-start Problem
- Exploration vs. Exploitation
- The Future of Recommender Systems
Throughout this article, I will continue to use examples of the companies that have built the most widely used systems over the last couple of years, including Airbnb, Amazon, Instagram, LinkedIn, Netflix, Spotify, Uber Eats, and YouTube.
Evaluation Metrics
Now that we have the algorithm for our Recommender System, we need to find a way to evaluate its performance. As with every Machine Learning model, there are two types of evaluation:
- Offline Evaluation
- Online Evaluation
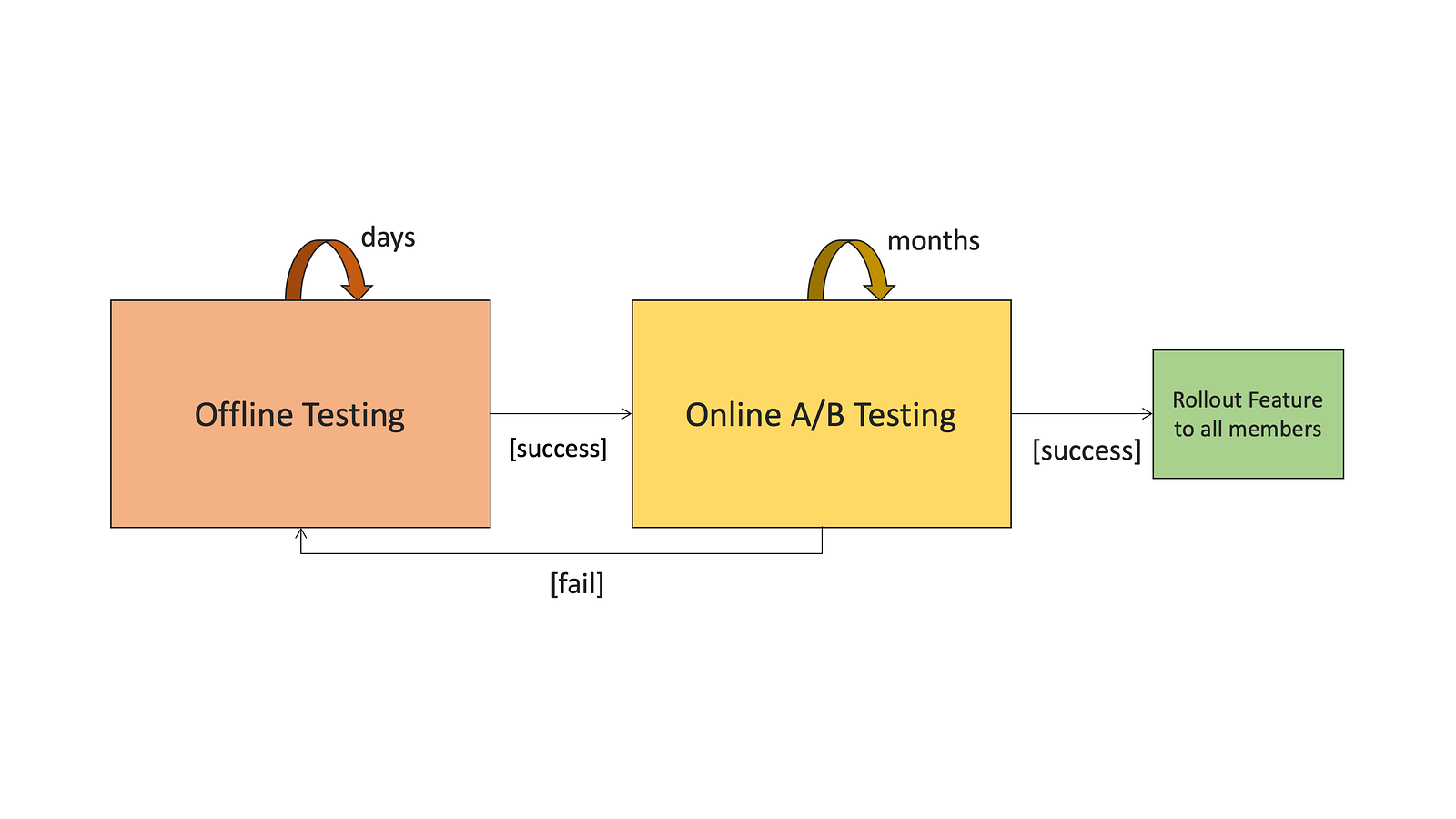
Generally speaking, we can consider the Offline Evaluation metrics as low-level metrics, that are usually easily measurable. The most well-known example would be Netflix choosing to use root mean squared error (RMSE) as a proxy metric for their Netflix Prize Challenge. The Online Evaluation metrics are the high-level business metrics that are only measurable as soon as we ship our model into the real world and test it with real users. Some examples include customer retention, click-through rate, or user engagement.
Offline Evaluation
As most of the existing Recommender Systems consist of two stages (candidate generation and ranking), we need to pick the right metrics for each stage. For the candidate generation stage, YouTube, for instance, focuses on high precision so “out of all the videos that were pre-selected how many are relevant”. This makes sense given that in the first stage we want to filter for a smaller set of videos whilst making sure all of them are potentially relevant to the user. In the second stage, presenting a few “best” recommendations in a list requires a fine-level representation to distinguish relative importance among candidates with high recall (“how many of the relevant videos did we find”).
Often, most of the examples are using the standard evaluation metrics used in the Machine Learning community: from ranking measures, such as normalized discounted cumulative gain, mean reciprocal rank, or fraction of concordant pairs, to classification metrics including accuracy, precision, recall, or F-score.
Instagram formulated the optimization function of their final pass model a little different:
We predict individual actions that people take on each piece of media, whether they’re positive actions such as like and save, or negative actions such as “See Fewer Posts Like This” (SFPLT). We use a multi-task multi-label (MTML) neural network to predict these events.
As appealing as offline experiments are, they have a major drawback: they assume that members would have behaved in the same way, for example, playing the same videos, if the new algorithm being evaluated had been used to generate the recommendations. That’s why we need online evaluation to measure the actual impact our model has on the higher-level business metrics.
Online Evaluation
The approach to be aware of here is A/B testing. There are many interesting and exhaustive articles/courses that cover this well, therefore I won’t spend too much time on this. The only slight variation I have encountered is Netflix’s approach called “Consumer Data Science” that you can read about it here.
The most popular high-level metrics that companies are measuring here are Click-Through Rate and Engagement. Uber Eats goes further here and designed a multi-objective tradeoff that captures multiple high-level metrics to account for the overall health of their three-sided marketplace (among others: Marketplace Fairness, Gross Bookings, Reliability, Eater Happiness). In addition to medium-term engagement, Netflix focuses on member retention rates as their online tests can range from between 2–6 months.
YouTube famously prioritizes watch-time over click-through rate. They even wrote an article, explaining why:
Ranking by click-through rate often promotes deceptive videos that the user does not complete (“clickbait”) whereas watch time better captures engagement
Evaluating Embeddings
As covered in the section on algorithms, embeddings are a crucial part of the candidate generation stage. However, unlike with a classification or regression model, it’s notoriously difficult to measure the quality of an embedding given that they are often being used in different contexts. A sanity check we can perform is to map the high-dimensional embedding vector into a lower-dimensional representation (via PCA, t-SNE, or UMAP) or apply clustering techniques such as k-means and then visualize the results. Airbnb did this with their listing embeddings to confirm that listings from similar locations are clustered together.
User Interface
For a Machine Learning Engineer or Data Scientist, the probably most overlooked aspect of the equation is the User Interface. The problem is that if your UI does not contain the needed components to showcase the recommendations or showcases them in the wrong context, the feedback loop is inherently flawed.
Let’s take Linkedin as an example to illustrate this. If I’m browsing through people’s profiles, on the right-hand side of the screen I see recommendations for similar people. When I’m browsing through companies, I see recommendations for similar companies. The recommendations are adapted to my current goals and context and encourage me to keep browsing the site. If the similar companies recommendations would appear on a person’s profile, I would probably be less encouraged to click on their profile as it is not what I am currently looking for.
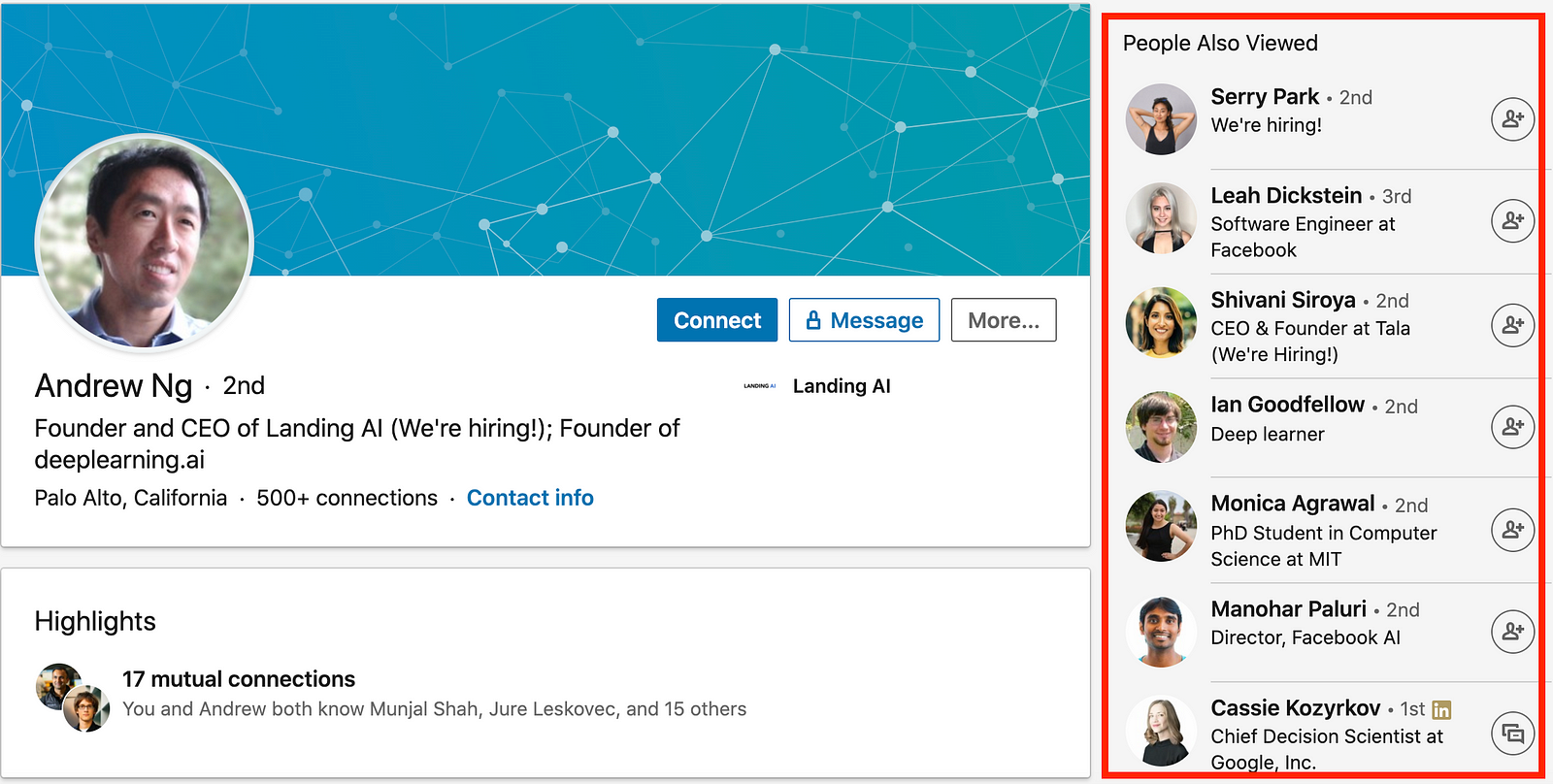
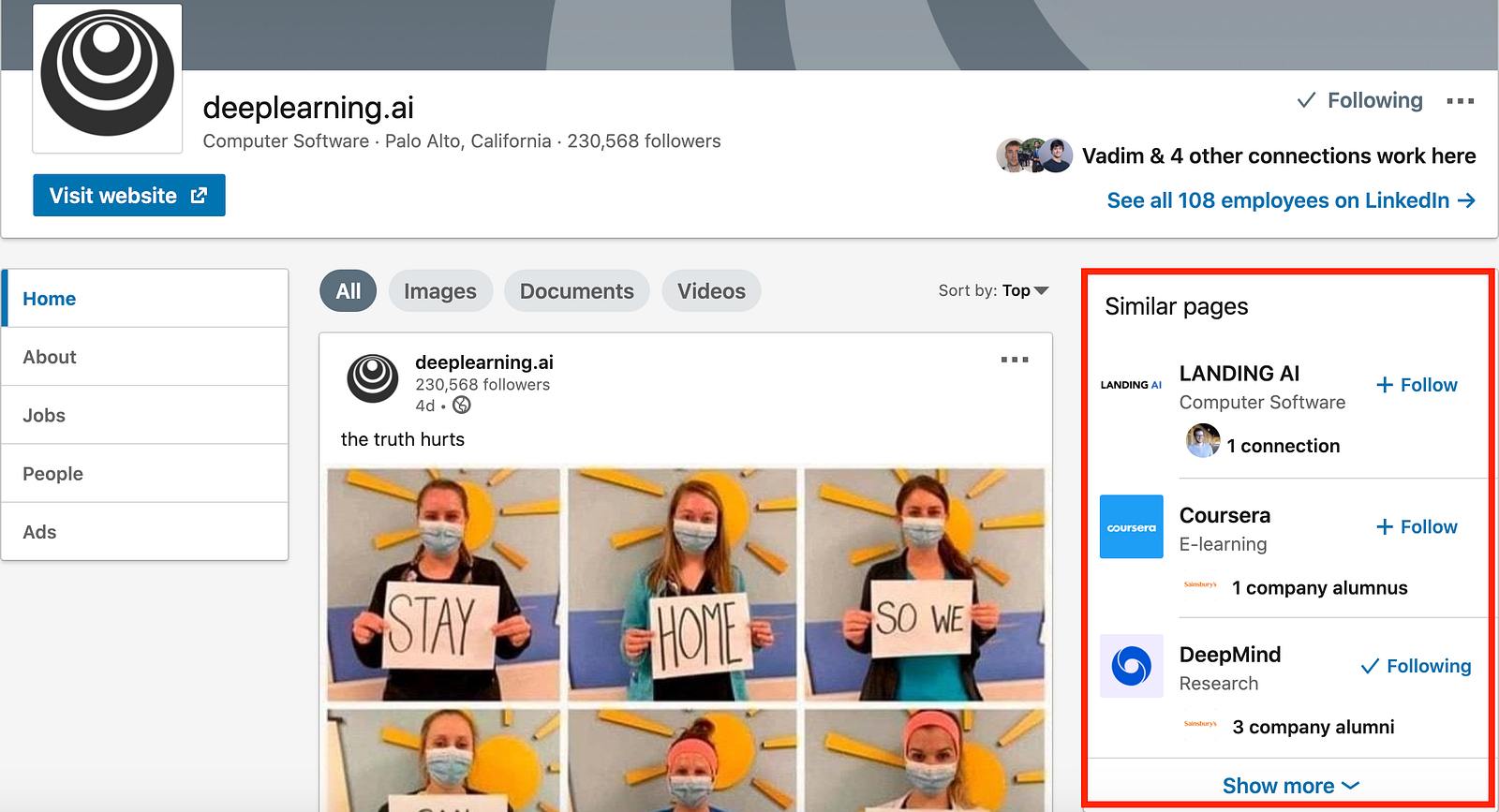
You can build the best Recommender System in the world, however, if your interface is not designed to serve the user’s needs and wants, no one will appreciate the recommendations. In fact, the User Interface challenge is so crucial that Netflix turned all components on their website into dynamic ones which are assembled by a Machine Learning algorithm to best reflect the goals of a user.
Spotify followed that model and adopted a similar layout for their home screen design, as can be seen below.
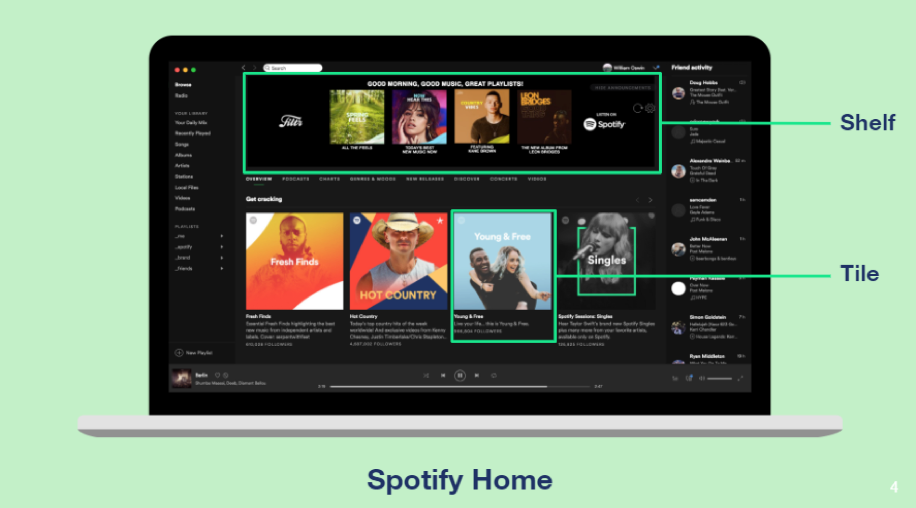
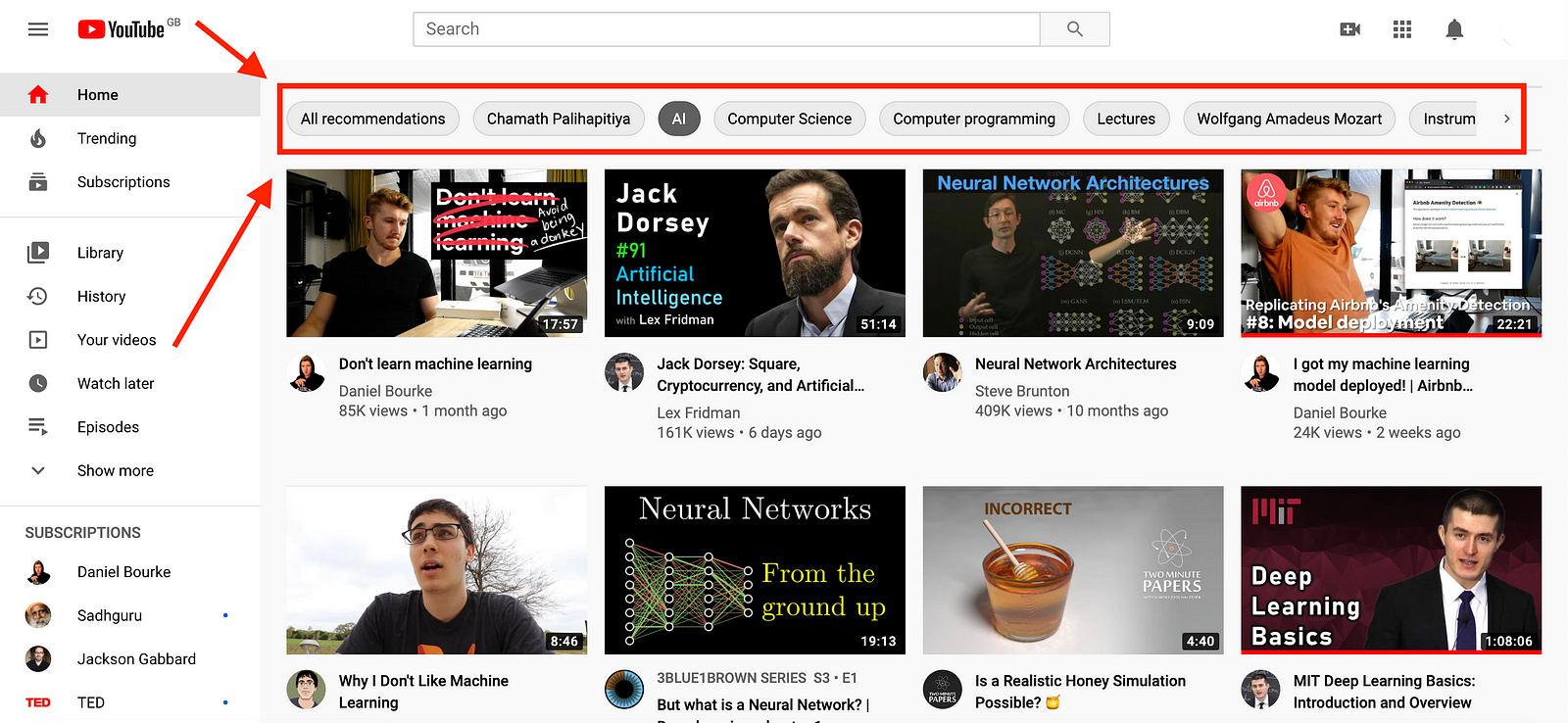
This is an ongoing area where there is still a lot of experimentation. As an example, YouTube recently changed their homepage interface to enable users to narrow down the recommendations for different topics:
Cold-start Problem
The cold-start problem is often seen in Recommender Systems because methods such as collaborative filtering rely heavily on past user-item interactions. Companies are confronted with the cold-start problem in two ways: user and item cold-start. Depending on the type of platform, either one of them is more prevalent.
User cold-start
Imagine a new member signs up for Netflix. At this point, the company doesn’t know anything about the new members’ preferences. How does the company keep her engaged by providing great recommendations?
In Netflix’s case, new members get a one-month free trial, during which cancellation rates are the highest while they decrease quickly after that. This is why any improvements to the cold-start problem present an immense business opportunity for Netflix, in order to increase engagement and retention in those first 30 days. Today, their members are given a survey during the sign-up process, during which they are asked to select videos from an algorithmically populated set that is then used as an input into all of their algorithms.
Item cold-start
Companies face a similar challenge when new items or content are added to the catalog. Platforms like Netflix or Prime Video hold an existing catalog of media items that changes less frequently (it takes time to create movies or series!), therefore they struggle less with this. On the contrary, on Airbnb or Zillow, new listings are created every day and at that point, they do not have an embedding as they were not present during the training process. Airbnb solves this the following way:
To create embeddings for a new listing we find 3 geographically closest listings that do have embeddings, and are of same listing type and price range as the new listing, and calculate their mean vector.
For Zillow, this is especially critical as some of the new home listings might only be on the site for a couple of days. They creatively solved this problem by creating a neural network-based mapping function from the content space to the embedding space, which is guided by the engagement data from users during the learning phase. This allows them to map a new home listing to the learned embedding space just by using its features.
Exploration vs. Exploitation
The concept of exploration/exploitation can be seen as the balancing of new content with well-established content. I was going to illustrate this concept myself, while I found this great excerpt that hits it right out of the ballpark:
“Imagine you’ve just entered an ice cream shop. You now face a crucial decision — out of about 30 flavors you need to choose only one!
You can go with two strategies: either go with that favorite flavor of yours that you already know is the best; or explore new flavors you never tried before, and maybe find a new best flavor.
These two strategies — exploitation and exploration — can also be used when recommending content. We can either exploit items that have high click-through rate with high certainty — maybe because these items have been shown thousands of times to similar users, or we can explore new items we haven’t shown to many users in the past. Incorporating exploration into your recommendation strategy is crucial — without it, new items don’t stand a chance against older, more familiar ones.”
(Source: Recommender Systems: Exploring the Unknown Using Uncertainty)
This tradeoff is a typical reinforcement learning problem and a commonly used approach is the multi-armed bandit algorithm. This is used by Spotify for the personalization of each users’ home page as well as Uber Eats for personalized recommendations optimized for their three-sided marketplace. Two scientists at Netflix gave a great talk about how they are using the MAB framework for movie recommendations.
Though I should mention that this is, by no means, the final solution to this problem, it seems to work for Netflix, Spotify, and Uber Eats, right?
Yes. But!
Netflix has roughly 160 million users and about 6.000 movies/shows. Spotify has about 230 million users and 50 million songs + 500.000 podcasts.
Twitter’s 330 million active users generate more than 500 million tweets per day (350.000 tweets per minute, 6.000 tweets per second). And then there’s YouTube, with its 300 hours of videos uploaded every minute!
The exploration space in the two latter cases is a little bit bigger than in the case of Netflix or Uber Eats, which makes the problem a lot more challenging.
The Future of Recommender Systems
This is the end of my little survey over Recommender Systems. As we have observed, Recommender Systems already guide so many aspects of our life. All the algorithms we covered over the course of these two articles are competing for our attention every day. And after all, they are all maximizing the time spent on their platform. As I illustrated in the section on Evaluation methods, most of the algorithms are optimizing for something like Click-through rate, engagement, or in YouTube’s case: watch time.
What does that mean for us as a consumer?
What it means is, that we are not in control of our desires anymore. While this might sound poetic, think about it. Let’s look at YouTube; we all have goals when coming to the site. We might want to listen to music, watch something funny, or learn something new. But all the content that is recommended to us (either through the Home Page recommendations, Search Ranking, or Watch Next) is optimized to keep us on the site for longer.
Lex Fridman and François Chollet had a great conversation about this on the Artificial Intelligence Podcast. Instead of choosing the metric to optimize for, what if companies would put the user in charge of choosing their own objective function? What if they would take the personal goals of the user’s profile into account and ask the user, what do you want to achieve? Right now, this technology is almost like our boss and we’re not in control of it. Wouldn’t it be incredible to leverage the power of Recommender Systems to be more like a mentor, a coach, or an assistant?
Imagine, as a consumer, you could ask YouTube to optimize the content to maximize learning outcomes. The technology is certainly already there. The challenge would really lie in aligning this with the existing business models and designing the right interface to empower the user to make that choice, and also to change as their goals evolve. With its new interface, YouTube is perhaps already taking baby-steps in that direction by putting the user in charge to select categories that she wants to see recommendations for. But this is just the beginning.
Could this be the way forward or is this just a consumer’s dream?
Resources
François Chollet: Keras, Deep Learning, and the Progress of AI | Artificial Intelligence Podcast
Airbnb — Listing Embeddings in Search Ranking
Airbnb — Machine Learning-Powered Search Ranking of Airbnb Experiences
Amazon — Amazon.com Recommendations Item-to-Item Collaborative Filtering
Amazon — The history of Amazon’s recommendation algorithm
Instagram — Powered by AI: Instagram’s Explore recommender system
LinkedIn — The Browsemaps: Collaborative Filtering at LinkedIn
Netflix — Netflix Recommendations: Beyond the 5 stars (Part 1)
Netflix — Netflix Recommendations: Beyond the 5 stars (Part 2)
Netflix — The Netflix Recommender System: Algorithms, Business Value, and Innovation
Netflix — Learning a Personalized Homepage
Pandora — Pandora’s Music Recommender
Spotify — Discover Weekly: How Does Spotify Know You So Well?
Spotify — For Your Ears Only: Personalizing Spotify Home with Machine Learning
Spotify — From Idea to Execution: Spotify’s Discover Weekly
Uber Eats — Food Discovery with Uber Eats: Recommending for the Marketplace
Uber Eats — Food Discovery with Uber Eats: Using Graph Learning to Power Recommendations
YouTube — The YouTube Video Recommendation System
YouTube — Collaborative Deep Learning for Recommender Systems
YouTube — Deep Neural Networks for YouTube Recommendations
Zillow — Home Embeddings for Similar Home Recommendations
Andrew Ng’s Machine Learning Course (Recommender Systems)
Google’s Machine Learning Crash Course — Embeddings