Recommender Systems: The Most Valuable Application of Machine Learning (Part 1)
Why Recommender Systems are the most valuable application of Machine Learning and how Machine Learning-driven Recommenders already drive almost every aspect of our lives.
Why Recommender Systems are the most valuable application of Machine Learning and how Machine Learning-driven Recommenders already drive almost every aspect of our lives.
Look back at your week: a Machine Learning algorithm determined what songs you might like to listen to, what food to order online, what posts you see on your favorite social networks, as well as the next person you may want to connect with, what series or movies you would like to watch, etc…
Machine Learning already guides so many aspects of our life without us necessarily being conscious of it. All of the applications mentioned above are driven by one type of algorithm: recommender systems.
In this article, I will explore and dive deeper into all the aspects that come into play to build a successful recommender system. The length of this article got a little out of hand so I decided to split it into two parts. This first part will cover:
- Business Value
- Problem Formulation
- Data
- Algorithms
The Second Part will cover:
- Evaluation Metrics
- User Interface
- Cold-start Problem
- Exploration vs. Exploitation
- The Future of Recommender Systems
Throughout this article, I will be using examples of the companies that have built the most widely used systems over the last couple of years, including Airbnb, Amazon, Instagram, LinkedIn, Netflix, Spotify, Uber Eats, and YouTube.
Business Value
Harvard Business Review made a strong statement by calling Recommenders the single most important algorithmic distinction between “born digital” enterprises and legacy companies. HBR also described the virtuous business cycle these can generate: the more people use a company’s Recommender System, the more valuable they become and the more valuable they become, the more people use them.
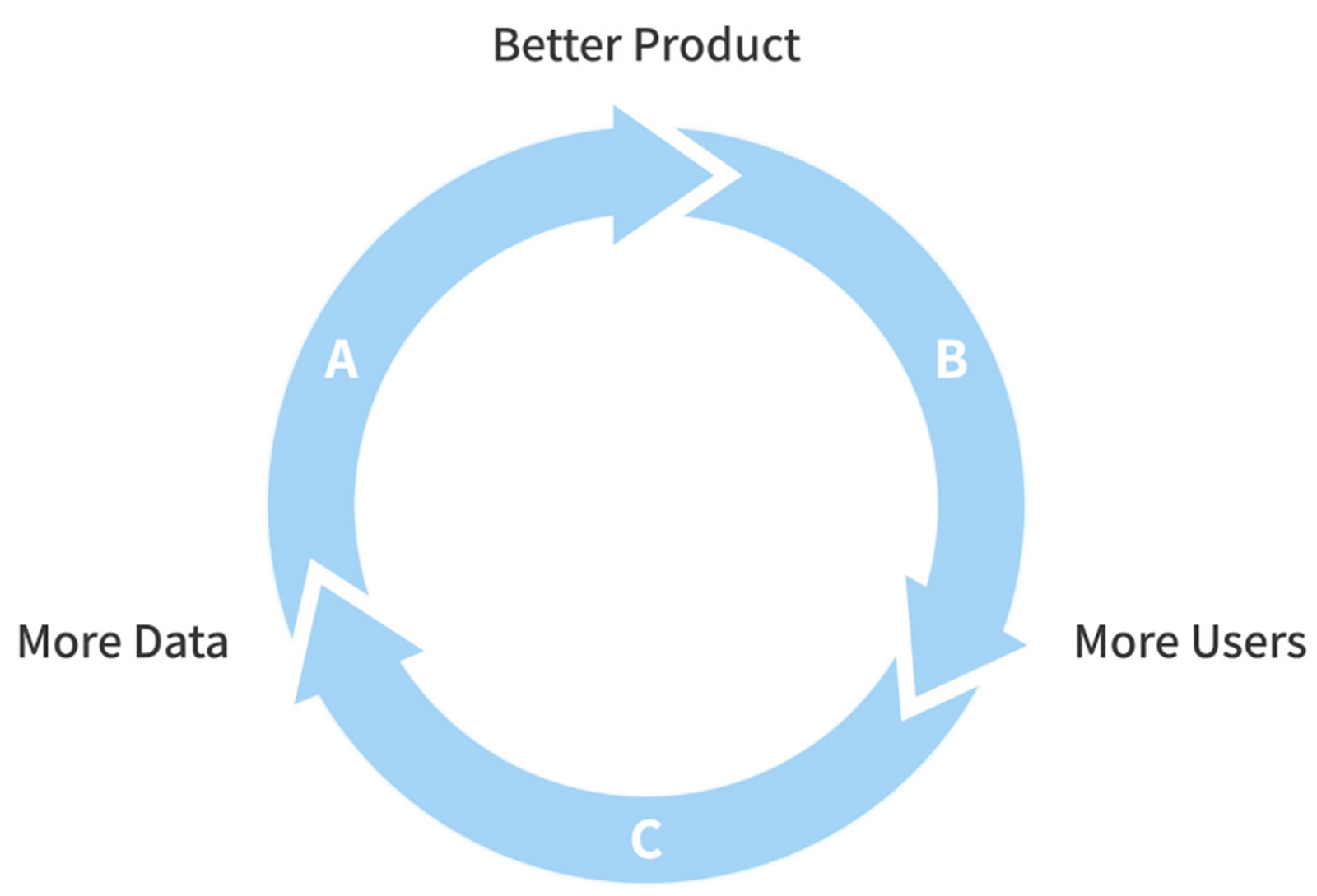
We are encouraged to look at recommender systems, not as a way to sell more online, but rather to see it as a renewable resource for relentlessly improving customer insights and our own insights as well. If we look at the illustration above, we can see that many legacy companies also have tons of users and therefore tons of data. The reason their virtuous cycle has not picked up as much as the ones off Amazon, Netflix or Spotify is because of the lack of knowledge on how to convert their user data into actionable insights, which can then be used to improve their product or services.
Looking at Netflix, for example, shows how crucial this is, as 80% of what people watch comes from some sort of recommendation. In 2015, one of their papers quoted:
“We think the combined effect of personalization and recommendations save us more than $1B per year.”
If we look at Amazon, 35% of what customers purchase at Amazon comes from product recommendations and at Airbnb, Search Ranking and Similar Listings drive 99% of all booking conversions.
Problem Formulation
Now that we’ve seen the immense value, companies can gain from Recommender Systems, let’s look at the type of challenges that can be solved by them. Generally speaking, tech companies are trying to recommend the most relevant content to their users. That could mean:
- similar home listings (Airbnb, Zillow)
- relevant media, e.g. photos, videos and stories (Instagram)
- relevant series and movies (Netflix, Amazon Prime Video)
- relevant songs and podcasts (Spotify)
- relevant videos (YouTube)
- similar users, posts (LinkedIn, Twitter, Instagram)
- relevant dishes and restaurants (Uber Eats)
The formulation of the problem is critical here. Most of the time, companies want to recommend content that users are most likely to enjoy in the future. The reformulation of this problem, as well as the algorithmic changes from recommending “what users are most likely to watch” to “what users are most likely to watch in the future” allowed Amazon PrimeVideo to gain a 2x improvement, a “once-in-a-decade leap” for their movie Recommender System.
“Amazon researchers found that using neural networks to generate movie recommendations worked much better when they sorted the input data chronologically and used it to predict future movie preferences over a short (one- to two-week) period.”
Data
Recommender Systems usually take two types of data as input:
- User Interaction Data (Implicit/Explicit)
- Item Data (Features)
The “classic”, and still widely used approach to recommender systems based on collaborative filtering (used by Amazon, Netflix, LinkedIn, Spotify and YouTube) uses either User-User or Item-Item relationships to find similar content. I’m not going to go deeper into the inner workings of this, as there are a lot of articles on that topic — like this one — that explain this concept well.
The user interaction data is the data we gather from the weblogs and can be divided into two groups:
Explicit data: explicit input from our users (e.g. movie ratings, search logs, liked, commented, watched, favorited, etc.)
Implicit data: information that is not provided intentionally but gathered from available data streams (e.g. search history, order history, clicked on, accounts interacted with, etc.)
The item data consists mainly of an item’s features. In YouTube’s case that would be a video’s metadata such as title and description. For Zillow, this could be a home’s Zip Code, City Region, Price, or Number of Bedrooms for instance.
Other data sources could be external data (for example, Netflix might add external item data features such as box office performance or critic reviews) or expert-generated data (Pandora’s Music Genome Project uses human input to apply values for each song in each of approximately 400 musical attributes).
A key insight here is that obviously, having more data about your users will inevitably lead to better model results (if applied correctly), however, as Airbnb shows in their 3-part journey to building a Ranking Model for Airbnb Experiences you can already achieve quite a lot with lesser data: the team at Airbnb already improved bookings by +13% with just 500 experiences and 50k training data size.
“The main take-away is: Don’t wait until you have big data, you can do quite a bit with small data to help grow and improve your business.”
Algorithms
Often, we associate Recommender Systems with just collaborative filtering. That’s fair, as in the past this has been the go-to method for a lot of the companies that have deployed successful systems in practice. Amazon was probably the first company to leverage item-to-item collaborative filtering. When they first released the inner workings of their method in a paper in 2003, the system had already been in use for six years.
Then, in 2006 Netflix followed suit with its famous Netflix Price Challenge which offered $1 million to whoever improved the accuracy of their existing system called Cinematch by 10%. Collaborative filtering was also a part of the early Recommender Systems at Spotify and YouTube. LinkedIn even developed a horizontal collaborative filtering infrastructure, known as Browsemaps. This platform enables rapid development, deployment, and computation of collaborative filtering recommendations for almost any use case on LinkedIn.
If you want to know more about collaborative filtering, I would recommend checking out Section 16 of Andrew Ng’s Machine Learning course on Coursera where he goes deeper into the math behind it.
Now, I would like to take a step back and generalize the concept of a Recommender System. While many companies used to rely on collaborative filtering, today there are a lot of other different algorithms at play that either complement or even replaced the collaborative filtering approach. Netflix went through this change when they shifted from a DVD shipping to a streaming business. As described in one of their papers:
“We indeed relied on such an algorithm heavily when our main business was shipping DVDs by mail, partly because in that context, a star rating was the main feedback that we received that a member had actually watched the video. […] But the days when stars and DVDs were the focus of recommendations at Netflix have long passed. […] Now, our recommender system consists of a variety of algorithms that collectively define the Netflix experience, most of which come together on the Netflix homepage.”
If we zoom out a little bit and look at Recommender Systems more broadly we find that they essentially consist of two parts:
- Candidate Generation
- Ranking
I am going to use YouTube’s Recommender System as an example below as they provided a good visualization, but that very same concept is applied by Instagram for recommendations in “Instagram Explore”, by Uber Eats in their Dish and Restaurant Recommender System, by Netflix for their movie recommendations and probably many other companies.
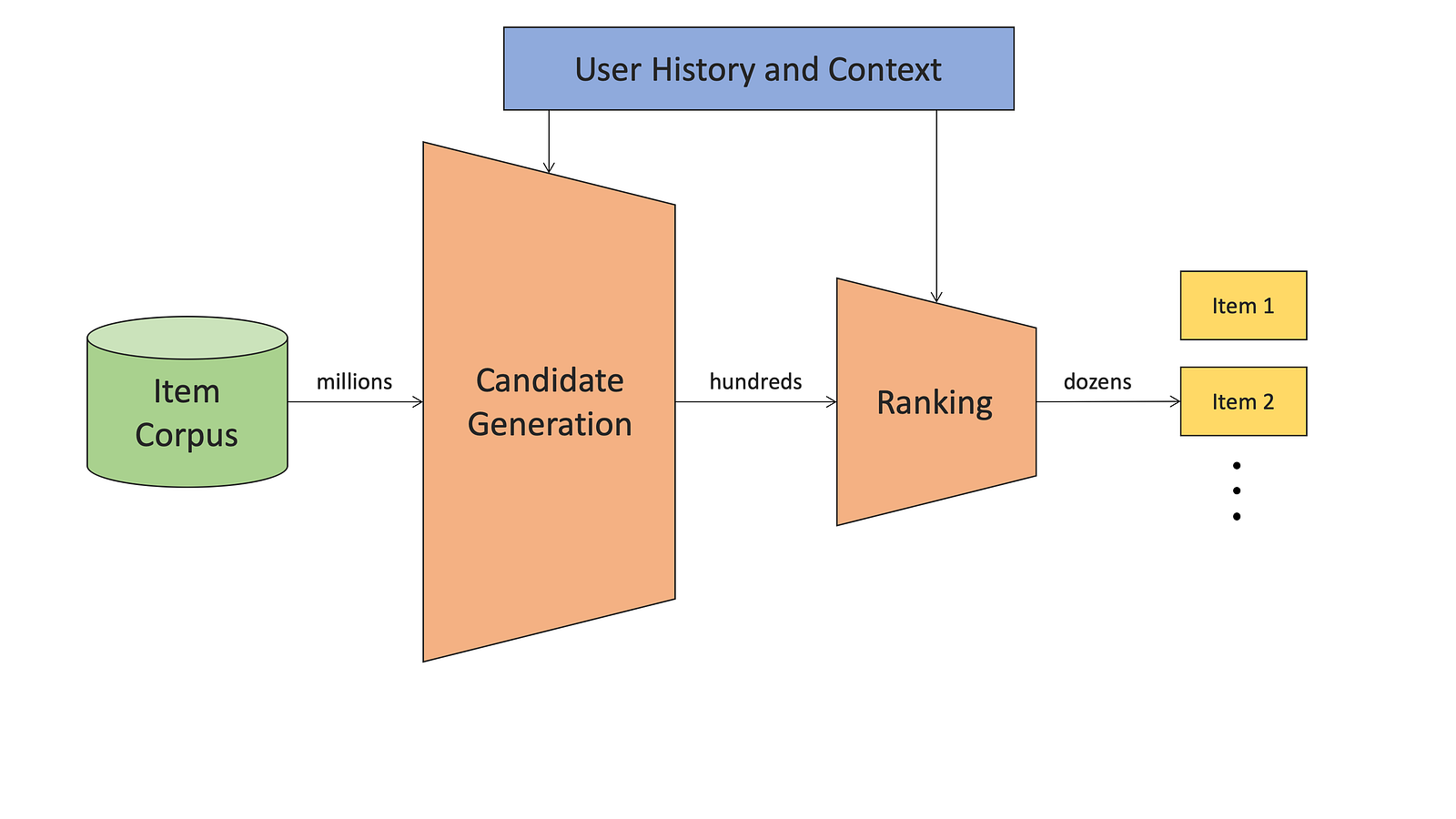
According to Netflix, the goal of Recommender Systems is to present a number of attractive items for a person to choose from. This is usually accomplished by selecting some items (candidate generation) and sorting them (ranking) in the order of expected enjoyment (or utility).
Let’s further investigate the two stages:
Candidate Generation
In this stage, we want to source the relevant candidates that could be eligible to show to our users. Here, we are working with the whole catalog of items so it can be quite large (YouTube and Instagram are great examples here). The key to doing this is entity embeddings. What are entity embeddings?
An entity embedding is a mathematical vector representation of an entity such that its dimensions might represent certain properties. Twitter has a great example of this in a blog post about Embeddings@Twitter: say we have two NBA players (Stephen Curry and LeBron James) and two musicians (Kendrick Lamar and Bruno Mars). We expect the distance between the embeddings of the NBA players to be smaller than the distance between the embeddings of a player and a musician. We can calculate the distance between two embeddings using the formula for Euclidean distance.
How do we come up with these embeddings?
Well, one way to do this would be collaborative filtering. We have our items and our users. If we put them in a matrix (for the example of Spotify) it could look like this:
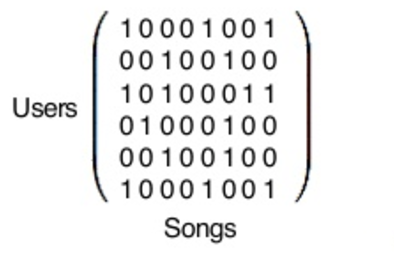
After applying the matrix factorization algorithm, we end up with user vectors and song vectors. To find out which users’ tastes are most similar to another’s, collaborative filtering compares one users’ vector with all of the other users’ vectors, ultimately spitting out which users are the closest matches. The same goes for the Y vector, songs: you can compare a single song’s vector with all the others, and find out which songs are most similar to the one in question.
Another way to do this takes inspiration from applications in the domain of Natural Language Processing. Researchers generalized the word2vec algorithm, developed by Google in the early 2010s to all entities appearing in a similar context. In word2vec, the networks are trained by directly taking into account the word order and their co-occurrence, based on the assumption that words frequently appearing together in the sentences also share more statistical dependence. As Airbnb describes, in their blog post about creating Listing Embeddings:
More recently, the concept of embeddings has been extended beyond word representations to other applications outside of NLP domain. Researchers from the Web Search, E-commerce and Marketplace domains have realized that just like one can train word embeddings by treating a sequence of words in a sentence as context, the same can be done for training embeddings of user actions by treating sequence of user actions as context. Examples include learning representations of items that were clicked or purchased or queries and ads that were clicked. These embeddings have subsequently been leveraged for a variety of recommendations on the Web.
Apart from Airbnb, this concept is used by Instagram (IG2Vec) to learn account embeddings, by YouTube to learn video embeddings and by Zillow to learn categorical embeddings.
Another, more novel approach to this is called Graph Learning and it is used by Uber Eats for their dish and restaurant embeddings. They represent each of their dishes and restaurant in a separate graph and apply the GraphSAGE algorithm to obtain the representations (embeddings) of the respective nodes.
And last but not least, we can also learn an embedding as part of the neural network for our target task. This approach gets you an embedding well customized for your particular system, but may take longer than training the embedding separately. The Keras Embedding Layer would be one way to achieve this. Google covers this well as part of their Machine Learning Crash Course.
Once we have this vectorial representation of our items we can simply use Nearest Neighbour Search to find our potential candidates.
Instagram, for example, defines a couple of seed accounts (accounts that people have interacted with in the past) and uses their IG2Vec account embeddings to find similar accounts that are like those. Based on these accounts, they are able to find the media that these accounts posted or engaged with. By doing that, they are able to filter billions of media items down to a couple thousand and then sample 500 candidates from the pool and send those candidates downstream to the ranking stage.
This phase can also be guided by business rules or just user input (the more information we have the more specific we can be). As Uber Eats mentions in one of their blog posts, for instance, pre-filtering can be based on factors such as geographical location.
So, to summarize:
In the candidate generation (or sourcing) phase, we filter our whole content catalog for a smaller subset of items that our users might be interested in. To do this we need to map our items into a mathematical representation called embeddings so we can use a similarity function to find the most similar items in space. There are several ways to achieve this. Three of them being collaborative filtering, word2vec for entities, and graph learning.
Ranking
Let’s loop back to the case of Instagram. After the candidate generation stage, we have about 500 media items that are potentially relevant and that we could show to a user in their “Explore” feed.
But which ones are going to be the most relevant?
Because, after all, there are only 25 spots on the first page of the “Explore” section. And if the first items suck, the user is not going to be impressed nor intrigued to keep browsing. Netflix’s and Amazon PrimeVideo’s web interface shows only the top 6 recommendations on the first page associated with each title in its catalog. Spotify’s Discover Weekly Playlist contains only 30 songs.
Also, all of this is subject to the users’ device. Smartphones, of course, allowing for less space for relevant recommendations than a web browser.
“There are many ways one could construct a ranking function ranging from simple scoring methods, to pairwise preferences, to optimization over the entire ranking. If we were to formulate this as a Machine Learning problem, we could select positive and negative examples from our historical data and let a Machine Learning algorithm learn the weights that optimize our goal. This family of Machine Learning problems is known as “Learning to rank” and is central to application scenarios such as search engines or ad targeting. In the ranking stage, we are not aiming for our items to have a global notion of relevance, but rather look for ways of optimizing a personalized model” (Extract from Netflix Blog Post).
To accomplish this, Instagram uses a three-stage ranking infrastructure to help balance the trade-offs between ranking relevance and computation efficiency. In the case of Uber Eats, their personalized ranking system is “a fully-fledged ML model that ranks the pre-filtered dish and restaurant candidates based on additional contextual information, such as the day, time, and current location of the user when they open the Uber Eats app”. In general, the level of complexity for your model really depends on the size of your feature space. Many supervised classification methods can be used for ranking. Typical choices include Logistic Regression, Support Vector Machines, Neural Networks, or Decision Tree-based methods such as Gradient Boosted Decision Trees (GBDT). On the other hand, a great number of algorithms specifically designed for learning to rank have appeared in recent years such as RankSVM or RankBoost.
To summarise:
After selecting initial candidates for our recommendations, in the ranking stage, we need to design a ranking function that ranks items by their relevance. This can be formulated as a Machine Learning problem, and the goal here is to optimize a personalized model for each user. This step is important because in most interfaces we have limited space to recommend items so we need to make the best use of that space by putting the most relevant items at the very top.
Baseline
As for every Machine Learning algorithm, we need a good baseline to measure the improvement of any change. A good baseline to start with is just to use the most popular items in the catalog, as described by Amazon:
“In the recommendations world, there’s a cardinal rule. If I know nothing about you, then the best things to recommend to you are the most popular things in the world.”
However, if you don’t even know what is most popular, because you just launched a new product or new items — as was the case with Airbnb Experiences — you can just randomly re-rank the item collection daily until you have gathered enough data for your first model.
That’s a wrap for Part 1 of this series. There are a couple of points I wanted to emphasize in this article:
- Recommender Systems are the most valuable application of Machine Learning as they are able to create a Virtuous Feedback Loop: the more people use a company’s Recommender System, the more valuable they become and the more valuable they become, the more people use them. Once you enter that Loop, the Sky is the Limit.
- The right Problem Formulation is key.
- In the Netflix Price Challenge, teams tried to build models that predict a users’ rating for a given movie. In the “real world”, companies use much more sophisticated data inputs which can be classified into two categories: Explicit and Implicit Data.
- In today’s world, Recommender Systems rely on much more than just Collaborative Filtering.
In the Second Part I will cover:
- Evaluation Metrics
- User Interface
- Cold-start Problem
- Exploration vs. Exploitation
Resources
Airbnb — Listing Embeddings in Search Ranking
Airbnb — Machine Learning-Powered Search Ranking of Airbnb Experiences
Amazon — Amazon.com Recommendations Item-to-Item Collaborative Filtering
Amazon — The history of Amazon’s recommendation algorithm
Instagram — Powered by AI: Instagram’s Explore recommender system
LinkedIn — The Browsemaps: Collaborative Filtering at LinkedIn
Netflix — Netflix Recommendations: Beyond the 5 stars (Part 1)
Netflix — Netflix Recommendations: Beyond the 5 stars (Part 2)
Netflix — The Netflix Recommender System: Algorithms, Business Value, and Innovation
Netflix — Learning a Personalized Homepage
Pandora — Pandora’s Music Recommender
Spotify — Discover Weekly: How Does Spotify Know You So Well?
Spotify — For Your Ears Only: Personalizing Spotify Home with Machine Learning
Spotify — From Idea to Execution: Spotify’s Discover Weekly
Uber Eats — Food Discovery with Uber Eats: Recommending for the Marketplace
Uber Eats — Food Discovery with Uber Eats: Using Graph Learning to Power Recommendations
YouTube — The YouTube Video Recommendation System
YouTube — Collaborative Deep Learning for Recommender Systems
YouTube — Deep Neural Networks for YouTube Recommendations
Zillow — Home Embeddings for Similar Home Recommendations